Recently I was tasked with sorting a list of countries, that were translated to Portuguese, in alphabetical order. Because the list contained special characters, “normal” Python .sort() was not working, putting the accented characters at the end of the list since their mathematical UTF8 representation was technically after the English alphabet.
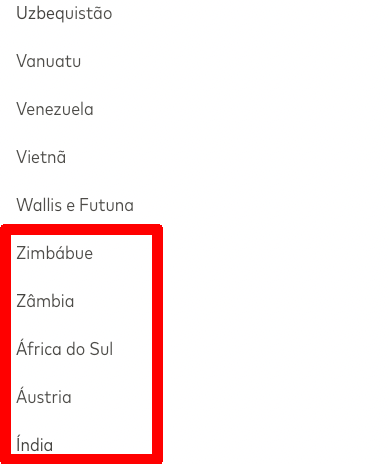
“África do Sul” should be sorted with the A-words at the top of the list even though the “Á” has a higher mathematical representation in code.
Enter collation. The definition of collate is: “compare and analyse (two or more sources of information).” We want to combine “normal” English alphabetical sorting with representation of accented characters.
It turns out there is a python library that exists already to make this very easy for us: pyuca: Python Unicode Collation Algorithm implementation.
To install, using poetry:
poetry add pyuca poetry update
Import the library in the python file you need it for:
from pyuca import Collator
Then in code, instantiate the pyuca collator object:
pyuca_collator = Collator()
And finally, sort the list using the pyuca collator instance:
options.sort(key=lambda option: pyuca_collator.sort_key(option["country_name"]))
The result is now the alphabetized list we’d expect, collating the special characters and sorting them accordingly.
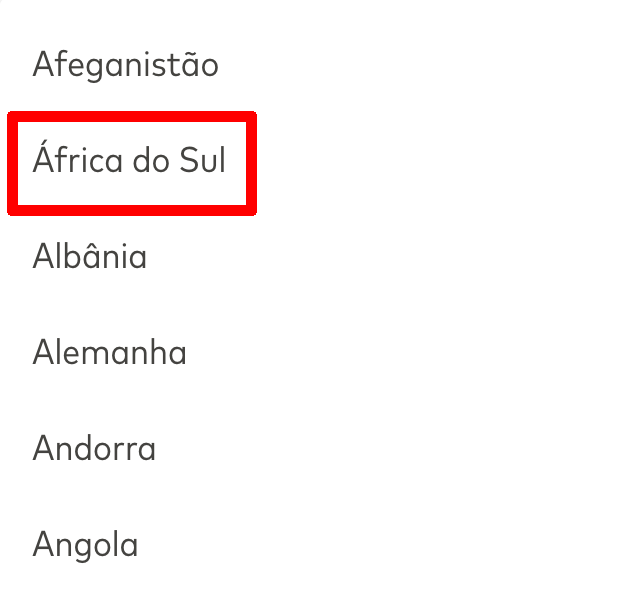
This example uses: Python, Django, poetry, pyuca